
“Static Recompliation” is the process of turning a binary program built for one instruction set and CPU into equivalent native code for a different architecture. It’s a hot topic lately as news of a static recompilation process for N64 games – turning the original MIPS code into x86 executables for Windows – seemingly promises an entirely new level of features and performance beyond existing emulation techniques. I’ve been interested in the topic since hearing of the StarCraft on ARM recompilation for OpenPandora in 2014, but not looked too much further into the idea until recently. I decided to try my own hand at a static recompiler, where I would be transforming some machine ROM into C source code, then compile that to produce native executables.
First, I’d need a source system to use: The CHIP-8 VM, often considered a good “baby’s first emulator” project. It is an interpreted 8-bit machine, with only 30 opcodes or so, limited graphics and sound capabilities and a lot of tooling available. I began by spending a couple of days implementing the machine in C as a plain “interpreted” emulator, using libcurses to handle keyboard input and display visuals on the terminal. This was useful for getting a feel for the machine, learning about quirks and addressing modes, as well as a benchmarking test. Some of the routines for interfacing the VM with the real hardware (e.g. “print screen”, “check keypress” etc) are theoretically reusable in a recompiled version as well. CHIP-8 emulation is a well-studied topic, I won’t say much more about it here.
With that complete, I turned my attention to the recompilation. If you’d like to see the code I wrote, I’ve placed it in GitHub here:
https://github.com/greg-kennedy/CURSE-8
Inside are the interpreter, and a Perl script “recompile.pl” which turns a .ch8 file into a .c. Compiling this along with “wrapper.c” and linking to libcurses should give a runnable executable of the chip8 program.
Details of approaches to static recompilation follow.
Basic Plan
A first approach to do this is something like so – a portion of the common “IBM Logo” program.
#include <stdint.h>
uint8_t RAM[4096] = { 0xF0, 0x90, 0x90, 0x90, 0xF0, // the starting font
0x20, 0x60, 0x20, 0x20, ...,
0x00, 0x00, 0x00, 0x00, 0x00, // padding to 0x200
0x00, 0x00, 0x00, 0x00, ...,
0x00, 0xe0, 0xa2, 0x2a, 0x60, // the contents of the ROM
0x0c, 0x61, 0x08, 0xd0, ...
};
void main() {
// machine variables
uint16_t I;
uint8_t v[0x10];
uint8_t timer_delay = 0, timer_sound = 0;
lbl_200: // decoded instruction at 0x200
screen_clear();
lbl_202:
I = RAM[0x22a];
lbl_204:
v[0x0] = 0x0c;
// remainder of disassembly
...
lbl_280:
screen_clear();
lbl_282:
screen_clear();
// alternate alignment decoding
lbl_201:
return; // ILLEGAL OPCODE
lbl_203:
// CALL lbl_a60;
...
}This copies the ROM into a block at the start of the program, then literally translates each opcode from 0x200 onwards into C code. It’s done twice, because CHIP-8 has no alignment restrictions but all opcodes are 2 bytes – and so the instructions after a JMP could be at odd-numbered locations instead.
Much of this is pretty straightforward, but there are two issues relating to control flow that deserve special mention:
- CALL and RETURN opcodes.
CALL and RETURN alter the PC on CHIP-8, but C code doesn’t allow that flexibility with “goto”. You can accomplish this with setjmp / longjmp instead. An array of jmp_buf and SP stack pointer works, like this, to “set” the return state on the stack and then later “longjmp” back to it.
#define STACK_DEPTH 16
jmp_buf stack[STACK_DEPTH];
uint8_t sp = 0;
#define CALL(x) if (setjmp(stack[sp])) sp --; else { sp ++; goto lbl_ # x; }
#define RET() longjmp(stack[sp - 1], sp);- Computed JMP opcode (BNNN)
CHIP-8 supports one opcode that allows computed JMP, by adding register v[0] to literal address NNN. Instruction sizes on the target machine may differ from those on source machine, so it’s not possible to just “add to the host Program Counter” as that won’t end up in the right spot. One way of handling this is to build a “jump table”: a big switch table and goto for each v0 value:
lbl_400: // consider opcode = "B500"
switch(v[0]) {
case 0: goto lbl_500;
case 1: goto lbl_501;
case 2: goto lbl_502;
...
case 255: goto lbl_5FF;
}Improvements
The above “works” but it’s very naive: it includes an entire copy of the ROM in the output binary, and it disassembles opcodes that don’t need disassembly (twice!). Wasteful, and hard to follow! Going back through this to clean up the source will be a nightmare.
Instead let’s adopt a two-step process, beginning with “static analysis” (parsing the binary to identify code paths and data regions) and then the translation to C source afterwards. Because CHIP-8 mixes instructions and data freely (curse you, von Neumann) it’s necessary to traverse the binary from the starting position 0x200, mark instructions as they’re crossed by the PC, and data as read / write when accessed by an instruction.
To figure out which instructions need translating, trace execution through the program and mark areas potentially visited by the PC. An example of doing the analysis, in Perl:
#!/usr/bin/env perl
use strict;
use warnings;
my @ram = load_rom();
my @map = ( (0) x 4096 );
sub trace {
my $pc = shift;
while (1) {
# instruction already visited, terminate
return if ($map[$pc] == 1);
# mark this location as Visited
$map[$pc] = 1;
# switch based on instruction types that affect the PC
if ($ram[$pc] == JUMP) {
# directly set PC to the address in the jump
$pc = $address;
} elsif ($ram[$pc] == CALL) {
# trace into the subroutine, then return to here and continue
trace($addresss);
$pc += 2;
} elsif ($ram[$pc] == RETURN) {
# return from subroutine call
return;
} elsif ($ram[$pc] == CONDITIONAL) {
# one of the instructions that conditionally skips the next line
# since we cannot know in advance whether the jump is taken,
# evaluate both branches
trace($addresss);
$pc += 2;
} elsif ($ram[$pc] == COMPUTED_JUMP) {
# as this could land anywhere from ADDR to ADDR + 255, step into each
# assume alignment (v[0] is even)
for (my $v = 2; $v < 255; $v += 2) {
trace($address + $v);
}
# continue at address
$pc = $address;
} else {
# other opcodes do not change control flow
$pc += 2;
}
}
}
trace(0x200);
# @map now contains a 1 for every position containing an instruction
# translate only those marked into code
# a further enhancement is to mark RAM access (read, write) as well
# translate those blocks to C arrays and ignore any otherWith a map in hand it’s possible to more intelligently turn the ROM data into C code. There is no need to translate unvisited values into instructions, nor to include the entire RAM contents – only those touched by read/write operations.
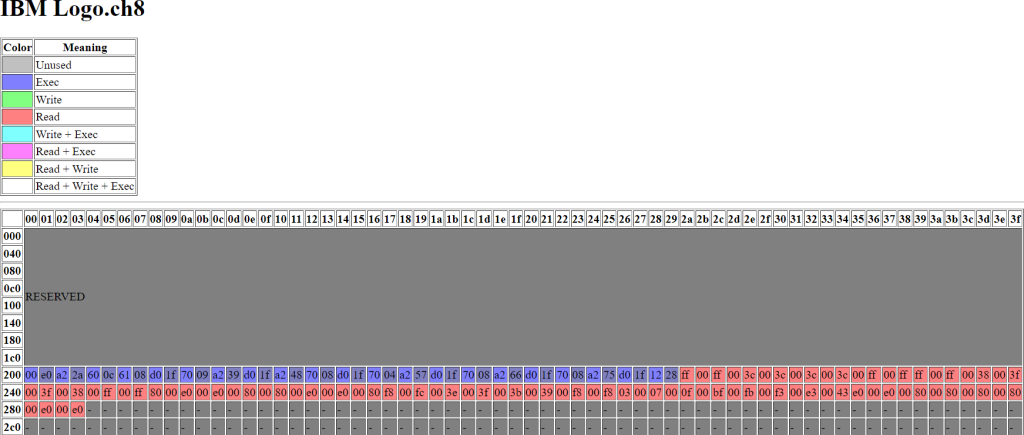
Here’s a visual I wrote that shows the RAM layout for analyzed ROMs. First, IBM Logo:
and then, UFO.ch8, a more advanced program with user input and multiple control changes:
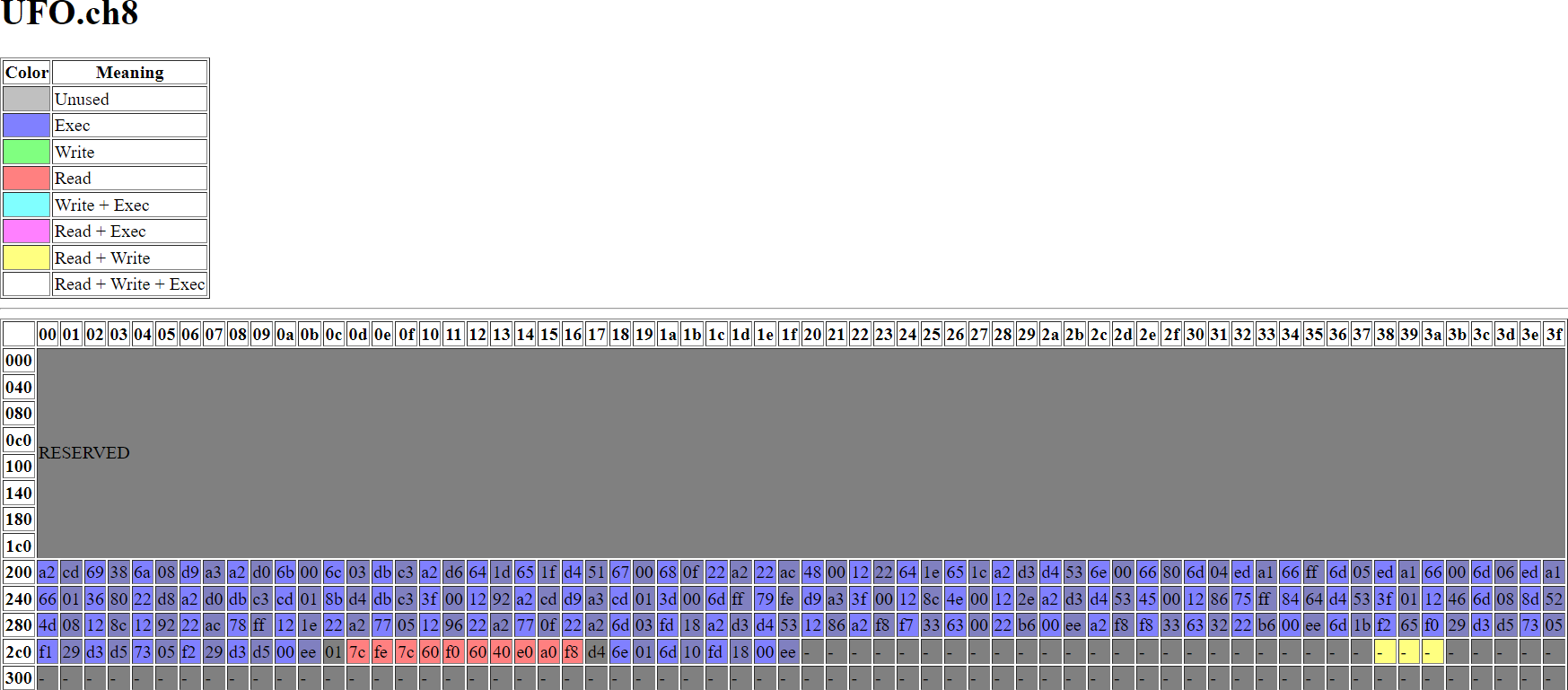
Static analysis brings other advantages as well, like finding dead code, uninitialized RAM reads, and the PC running off the memory page. Note the two bytes surrounding the sprite data (above), which are unused bytes.
For reference, here’s the C recompilation of IBM Logo after using the tracing as above.
void run() {
uint8_t ram_22a[] = { 0xff, 0x00, 0xff, 0x00, 0x3c, 0x00, 0x3c, 0x00, 0x3c, 0x00, 0x3c, 0x00, 0xff, 0x00, 0xff, 0xff, 0x00, 0xff, 0x00, 0x38, 0x00, 0x3f, 0x00, 0x3f, 0x00, 0x38, 0x00, 0xff, 0x00, 0xff, 0x80, 0x00, 0xe0, 0x00, 0xe0, 0x00, 0x80, 0x00, 0x80, 0x00, 0xe0, 0x00, 0xe0, 0x00, 0x80, 0xf8, 0x00, 0xfc, 0x00, 0x3e, 0x00, 0x3f, 0x00, 0x3b, 0x00, 0x39, 0x00, 0xf8, 0x00, 0xf8, 0x03, 0x00, 0x07, 0x00, 0x0f, 0x00, 0xbf, 0x00, 0xfb, 0x00, 0xf3, 0x00, 0xe3, 0x00, 0x43, 0xe0, 0x00, 0xe0, 0x00, 0x80, 0x00, 0x80, 0x00, 0x80, 0x00, 0x80, 0x00, 0xe0, 0x00, 0xe0 };
lbl_200:
screen_clear();
lbl_202:
i = ram_22a + 0x000;
lbl_204:
v[0x00] = 0x0c;
lbl_206:
v[0x01] = 0x08;
lbl_208:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_20a:
v[0x00] += 0x09;
lbl_20c:
i = ram_22a + 0x00f;
lbl_20e:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_210:
i = ram_22a + 0x01e;
lbl_212:
v[0x00] += 0x08;
lbl_214:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_216:
v[0x00] += 0x04;
lbl_218:
i = ram_22a + 0x02d;
lbl_21a:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_21c:
v[0x00] += 0x08;
lbl_21e:
i = ram_22a + 0x03c;
lbl_220:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_222:
v[0x00] += 0x08;
lbl_224:
i = ram_22a + 0x04b;
lbl_226:
screen_sprite( v[0x0], v[0x1], 0x0f );
lbl_228:
return;
}
Much simpler, and more accurate, than the first attempt!
Further Analysis with Bit Sets
It helps to think of the main goal of the analyzer as “reducing the amount of decompilation”. In the first pass we decompiled everything, and included the entire RAM contents, even though most of it was unnecessary or not actually executed. The instruction tracing is still missing things and could be refined further. Consider this assembly fragment:
v0 := 0x05
if v0 == 0x06 then
jump is_six
jump is_five
...
: is_five
# some instructions
: is_six
# different instructionsWith the code before, both paths will be evaluated. As a human looking at this, we recognize that the condition “if v0 == 0x06” will never be true, so the branch is never taken, and is_six is entirely dead code.
I improved on this by having the analyzer carry additional state data along during tracing: for each register, a 256-bit block where each bit position indicates a “possible” value held in the register at that point. So, for example, “v0 := 0x5” will clear the bit vector for v0 and then set position 5 to a 1 value, as the instruction eliminates all possibilities except 5 at that point. The subsequent check, “v0 == 0x06”, is done by ANDing the v0 with a bit vector in which only position 6 is set. The result vector – always 0 – indicates that the condition is never true, the jump never taken, and the entire branch eliminated.
The same change was made for I register, which has 4096 bits instead. Also, instead of returning when the PC has visited a location, it instead must check if the machine has already (potentially) been in the current exact state already, including the stack, through use of bit operations vs the RAM map. This gets very memory demanding! Decompiling UFO takes about 18 seconds on my machine, and I haven’t been able to get it to disassemble Chipquarium.ch8 successfully yet… oh well. Maybe if I rewrite this in C instead of Perl 🙂
Self-Modifying Code
There’s an elephant in the room in all this. Consider this assembly:
: main
i := 0x207
v0 := 5
save v0
v1 := 0
i := hex v1
sprite v0 v0 5This is an example of self-modifying code. The “save v0” instruction places the value 0x05 at location 0x207 – replacing the 0 in “v1 := 0” with “v1 := 5”. Running this program on an interpreter will show the number 5 on the screen. Running it with the decompiler shows 0, because the RAM address 0x207 no longer has anything to do with the code we generated and compiled.
There are solutions to this, like embedding an interpreter in your machine that works for self-modifying regions and falls back to the precompiled stuff otherwise. But I made a simpler decision: attempting to “write” an exec region, or “exec” a written region, just kills the analyzer instead.
$ ./recompile.pl slipperyslope.ch8
Deep recursion on subroutine "main::iterate" at ./recompile.pl line 282.
Write to executable memory 613 + 0 at 690, op = f055 at ./recompile.pl line 668.This unfortunately locks me out of a lot of newer CHIP-8 games, which use self-modifying code to change sprite tables and data regions. But at least I can play UFO.
Benchmarks
What’s the point of all this if it doesn’t go faster than pure interpretation? For a rough benchmark I used the “1dcell.ch8” program, which plots the results of each Rule of elementary cellular automata in a loop. Well, it’s difficult to do actual measurements (not least because ssh and curses make it very I/O bound), but here’s the program recompiled and running at top speed:

Anyway, I’m satisfied with this little experiment for now – while I have some ideas for further refinements, it certainly seems proven possible, and I have other projects to consider 🙂
Pingback: Static recompilation of CHIP-8 programs « Adafruit Industries – Makers, hackers, artists, designers and engineers!